Using Variance and Standard Deviation in Trip Rate Checks
June 24th, 2014During the peer review, one thing that we were told to look at was the variance in the cells of our cross-classification table.
Like all statistics, variance needs to be looked at in context with other statistics.  To illustrate this, I created some fake data In Excel.
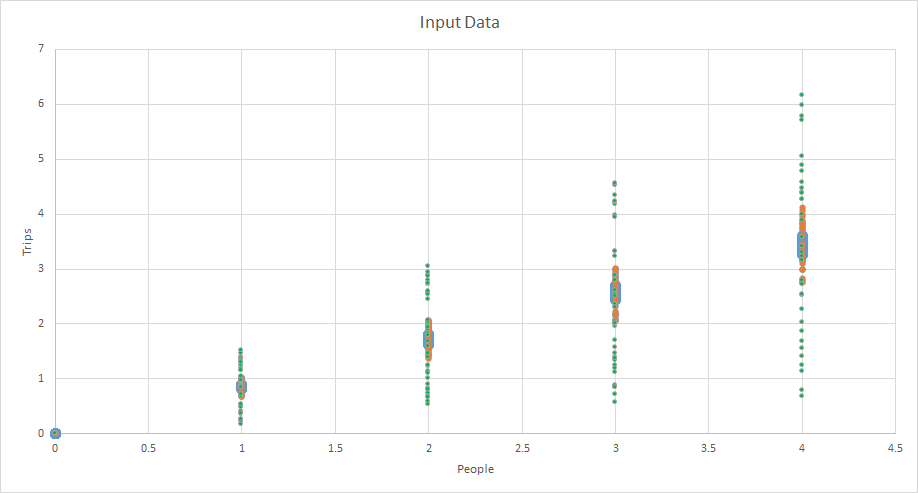
This is what the data looks like. It is all random and perfect, but you can see that some is “tighter” than others.
The first thing I looked at was the variance compared to the mean.
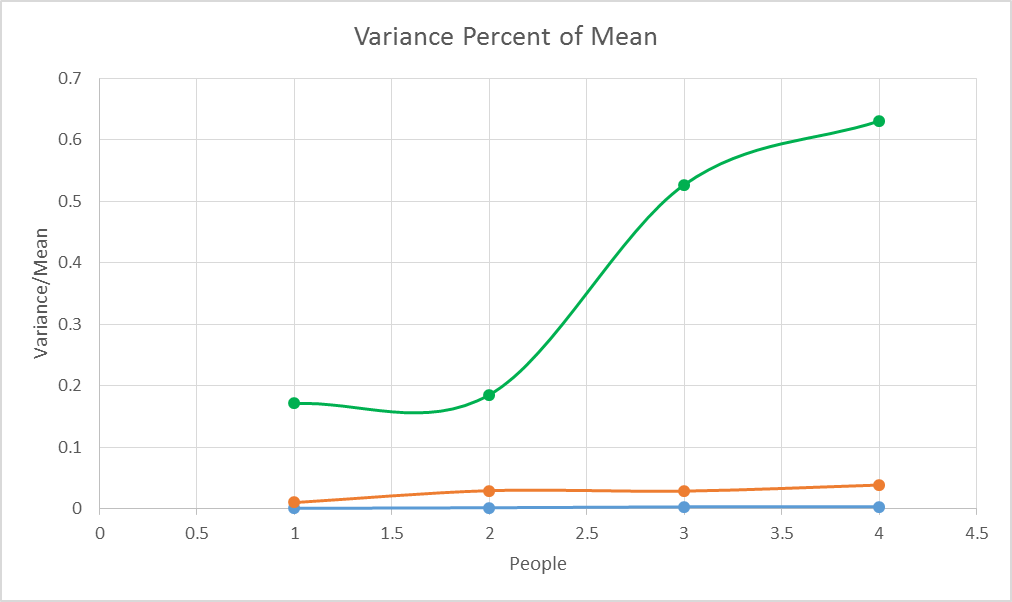
This is the variance compared to the mean. Note that the colors are the same as on the input sheet. The green line (which had the largest random scatter component) is way high compared to the other two, which are much more centralized around the mean.
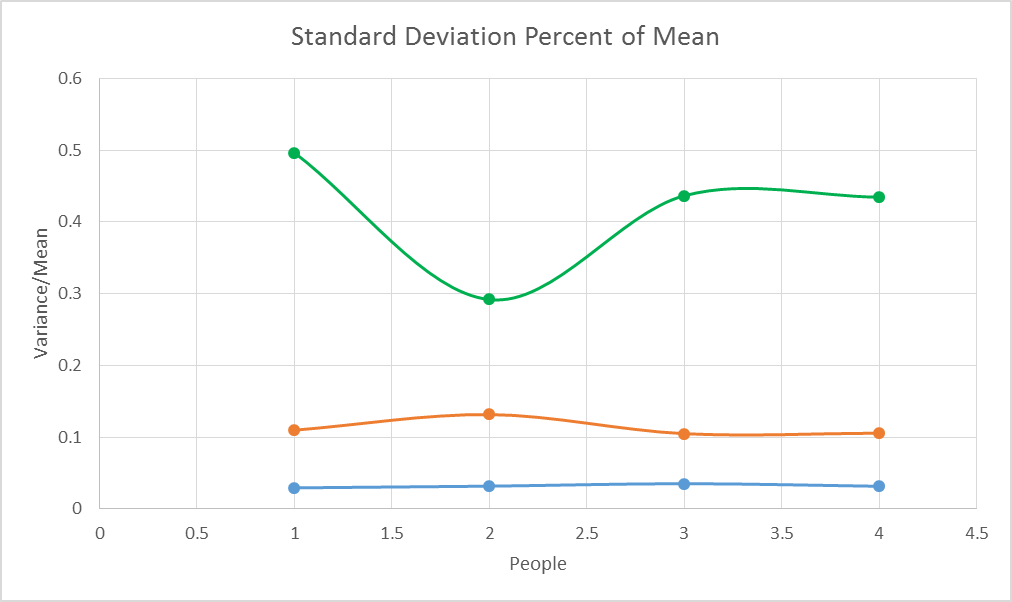
I looked at the standard deviation as well, but variance looks better to me.
What does this mean? Â Well, lets take a look at it using a subset of NHTS 2009 data.
I looked at the average trips per household by number of workers, and the table below lists the average by worker.
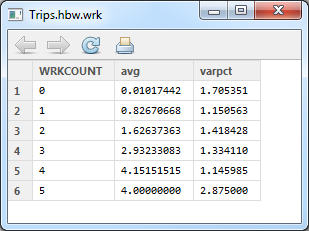
The var/mean (the varpct column in the table) is pretty high.  The correlation isn’t bad at 0.616.  However, there are 3,143 observed trips in the table, and this method results in the same number of trips.
Next, I looked at average trips per household by workers and income.
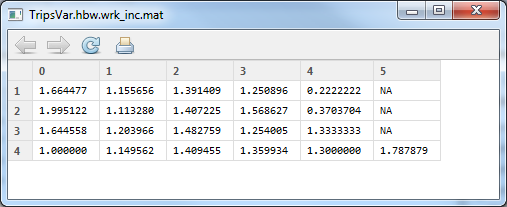
Variance/mean of trips
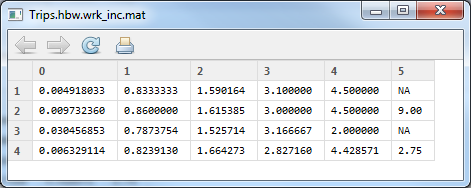
Average Trip Rates by HH
They’re a little better looking.  The correlation is 0.623, so that’s a little better, and the total trips is 3,143.  Yes, that is the exact number of trips in the table.  Looking at the sum of the difference (which in this case should be zero), it came up to -5.432×10^-14… that’s quite close to zero!
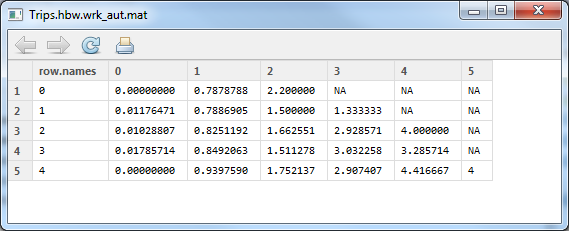
Mean trips per household by workers and autos (rows are autos, columns are workers)
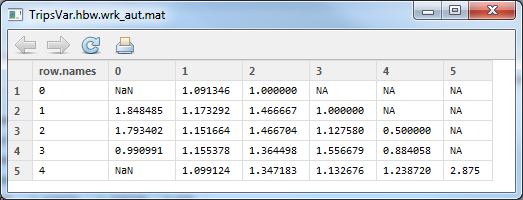
Variance/mean trips per household by workers and autos (rows are autos, columns are workers)
By workers and autos was similar – the correlation was 0.619, and the total trips is 3,143. Â Since it was the exact same number as the last time, I checked the difference in the same manner, and found that the total difference was 4.14×10^-14. Â Different by a HUGE (not!) amount.
Summary
There are a few things to look at.
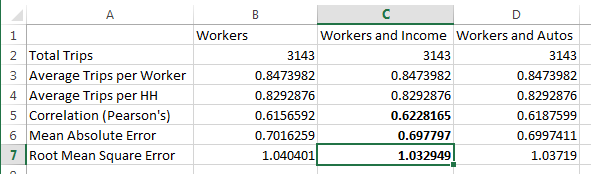
Summary of various factors.
Ultimately, this wasn’t as different as I hoped to show. Â I was hoping to show some bad data vs. good data from the NHTS, but without intentionally monkeying with the data, it was hard to get something better.
-A-




You must be logged in to post a comment.