Logsum Issues
February 11th, 2014I’ve been working through distribution in the model, and I was having a little bit of trouble. Â As I looked into things, I found one place where QC is necessary to verify that things are working right.
The Logsums.
I didn’t like the shape of the curve from the friction factors I was getting, so I started looking into a variety of inputs to the mode choice model. Â Like time and distance by car:
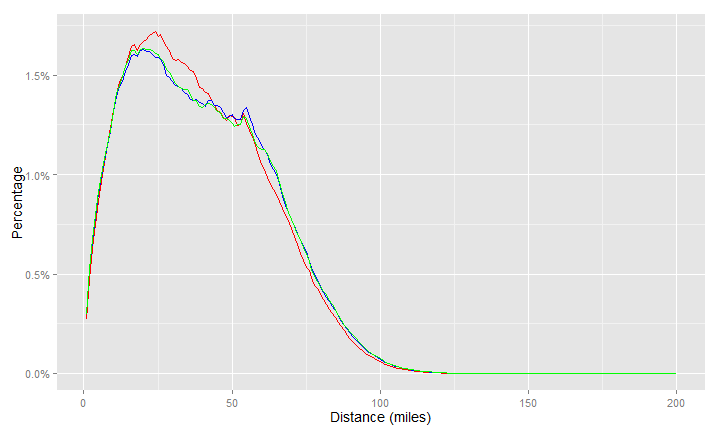
This is a comparison of distance. The red line is the new model, the blue and green are two different years of the old model.
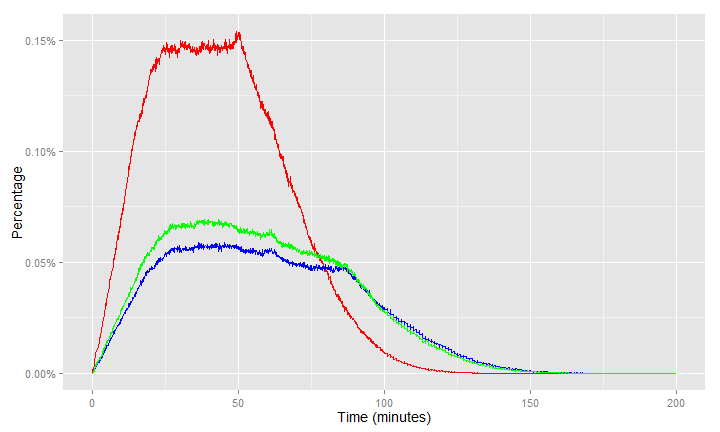
This is a comparison of zone-to-zone times. The red line is the new model, the blue and green are different years of the old model.
In both cases, these are as expected. Â Since there are more (smaller) zones in the new model, there are more shorter times and distances.
The problem that crept up was the logsums coming from mode choice model for use in distribution:
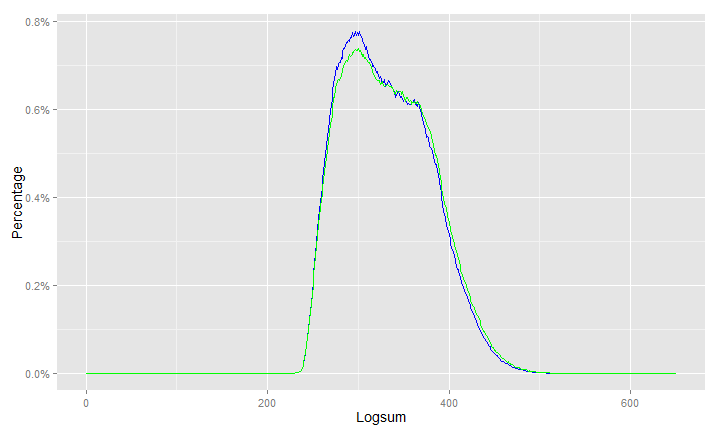
These are the logsums from the old model. Notice that the curve allows for some variation.
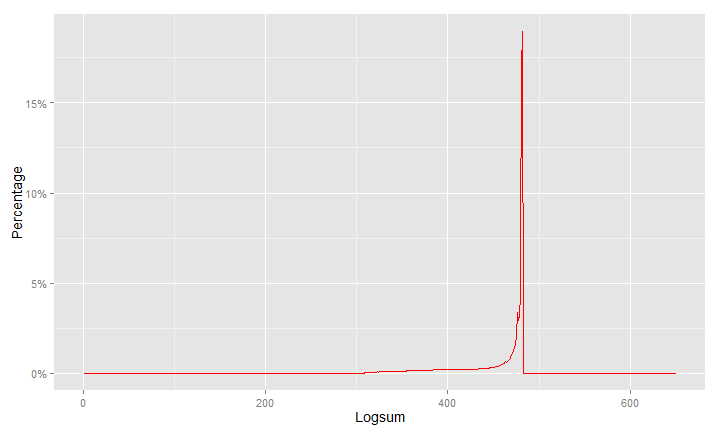
These are the logsums in the new model. This is a problem because of that ‘spike’.
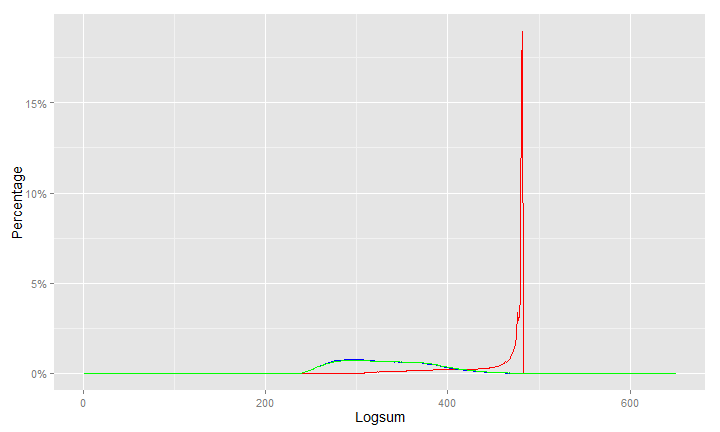
I put all the logsums on this, notice how the curve for the old model is dwarfed by the spike in the new model. This is bad.
So the question remains, what went wrong?
I believe the ultimate problem was that there was no limit on Bike and Pedestrian trips in the model, so it was generating some extreme values and somewhere and an infinity was happening in those modes causing the curve shown above. Â I tested this by limiting the pedestrian trips to 5 miles (a fairly extreme value) and bike trips to 15 miles and re-running. Â The logsums looked very different (again, the new model is the red line):
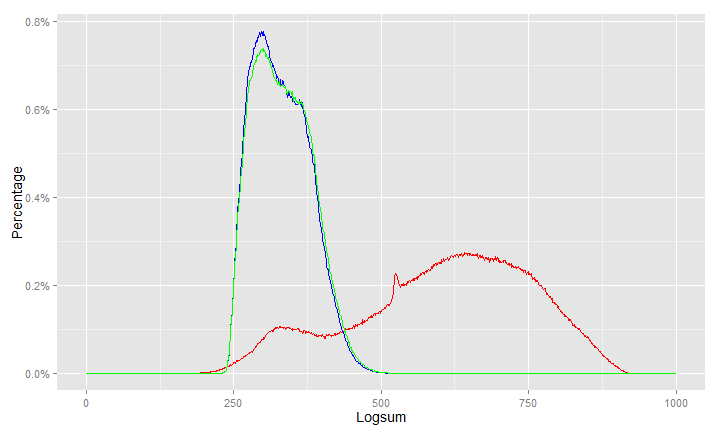
This is a comparison between the two model versions with fixed bicycle and pedestrian utility equations.
Note that the X axis range went from 650 (in the above plots) to 1000. Â I’m not too concerned that the logsums in the new model have a larger range. Â In fact, as long as those ranges are in the right place distribution may be better. Â This is not final data, as I am still looking at a few other things to debug.





You must be logged in to post a comment.