A few people have approached me about starting a blog. Â Sometimes it is about transportation, sometimes it isn’t. Â There are already a lot of guides out there, although many seem to assume you want to be a full-time blogger. Â The people I talk to do not want to be full-time bloggers, and I think some approaches may be a little different.
This post is in three parts – Getting Started, Moving Forward, and Final Words. Â The Getting Started part discusses the software and extensions used on my blogs (I run two blogs). Â Moving Forward discusses a variety of things to keep your blog interesting and also about maintaining the blog. Â The Final Words section is where I discuss many of the little things (and probably where the full-time bloggers will differ from me).
This is not intended to be a how-to. Â I’ve tried to write this in a way that someone could get familiar with WordPress and use this as a guide without the “click here, click here” stuff. Â If you can’t find something search the Internet. Â If you still can’t find it, either drop a comment, tweet me (@okiAndrew), contact me via Google+, use the contact form, or drop me an email if you have one of my email addresses.
Getting Started
I firmly advocate using WordPress, but my position is because I’ve used it for several years with ZERO issues. Â I’m fairly certain that people using Blogger (Google’s Blog Engine) and TypePad can say the same thing. Â Wordpress comes in two “flavors” – wordpress.org is the open source blogging software for use on your own server. Â In my case, my blog is hosted via BlueHost (and I pay for this service). Â Wordpress.com is a hosted free (I think) version of wordpress. Â I don’t know what compromises you have to make for free, but nothing is truly free (however, allowing ads on a wordpress.com site may be acceptable).
Setting up WordPress on your own server or for a hosting service is simple.
Once installed, the first things I would do:
- Rename the admin account from “admin” or “administrator” to something less common. Â This reduces your likelihood for an attack from those that would like to turn your blog into a spam center (trust me, they exist). Â Additionally, make sure your passwords are long, have numbers, letters (capital and lowercase) and have a symbol (or a few).
- Setup Plugins:
- Setup Akismet (anti-spam).
- Setup Jetpack add-ons
- Add and setup Login Security Solution
- Add and setup WordPress Database Backup. Â I have backups emailed to me on a daily basis.
- Add WordPress Editorial Calendar (you’ll see why later)
- Add WP-DBManager
- Add and setup WP Super Cache (this speeds up your site considerably)
- Add Shadowbox JS (and if wanted, Shadowbox JS – Use Title from Image) – this has images come up on the page as opposed to separate “pages” when clicked.
- Optional: add Syntax Highligher and Code Prettifier Plugin for WordPress – this is a code tool. Â I actually no longer use it because I’ve been using Github Gists.
- Optional: add Embed Github Gist – since I use Github Gists, this makes the experience much easier! Â If you’re not going to show code on your site, you can ignore this.
- Optional: add LaTeX for WordPress – I’ve used LaTeX only once, but it makes equations so much nicer. Â If you’re not going to show equations, ignore this.
- Optional: Setup Google Analytics and add Google Analyticator – this is one of many places where you can track ‘hits’.
- Don’t setup social sharing yet! Â You’ll see why.
- Either trash the first test post and comment and write your first post and page, or revise the first test post to something more substantial.
- In WordPress, posts are the weekly (or daily, monthly, etc). Â Pages are items that generally don’t change. Â I have four pages, and one of them is hidden.
- If you look somewhere on my site, you can see a heading for Pages, and under it are links to Contact Me, Travel Demand Modeling 101, and Welcome!. Â My feelings are that the Welcome and Contact pages are pretty important, and an about page is pretty important as well (maybe one day I’ll write one).
- The posts on my site are the front-and-center content
- I’ve seen a lot of bloggers claim that you should have a privacy policy and a comment policy. Â Truthfully, you don’t need them unless you have a lot of visits (over a few hundred, at least), and if you’re in that arena, you should probably be looking for professional blogger help (I am absolutely serious about that).
- You definitely want at least one post and one page before moving on to the next item. Â The post can be just a test post, but I would do more words than the basic test post that comes with WordPress.
- Find a better theme!
- In the Appearance area, you can find more themes. Â Many can be customized, or you can make your own.
- Find a theme that suits you. Â Many themes can be adjusted, and I would encourage you to tweak it a lot and make sure everything looks good before settling on one
- Making a custom theme is not the easiest thing to do. Â I’ve done it once (for this blog) and I’m tempted to do it again (for my other blog), but there is so much that goes into it that I don’t really advocate it.
- Categories
- Setup some categories. Â This is important in the permalinks structure, but can have some importance elsewhere.
- Fix Permanent Links
- In the WordPress Dashboard – Settings – Permalinks, change the default (e.g. www.siliconcreek.net/?p=123) to a custom structure of /%category%/%postname% . Â This works best for search engine optimization (SEO). Â This is one of the few things I do for SEO.
- Setup Social Sharing
- If you’re going to be a blogger, you generally should have a few things already:
- Twitter
- LinkedIn (IF your blog is professional related)
- Facebook (IF your blog is personal)
- You want to setup sharing to automatically post new posts to the correct platforms. Â Keep in mind that the “other” content of your social media should relate to the blog and vice-versa… What I mean by this is that I don’t post amateur radio stuff to my @okiAndrew twitter feed or to LinkedIn and likewise, I don’t post transportation stuff to my @KE8P twitter account. Â Different accounts for different uses. Â I don’t advocate mixing too much (there are links between the two, but I expect users that are interested in the “two me’s” to deal with the social media side on their end).
- If you think the social media side isn’t important, think again. Â Over the past 6 months, most of the tracked referrers was from LinkedIn and Twitter (the t.co referrer) – both around equal shares. Â They were ~4 times the third-place referrer.
Once these items are completed, you’re ready to move forward!
Moving Forward
So moving forward obviously means “write content!”. Â And that’s something you should do.
I advocate publishing on a weekly basis. Â This generally doesn’t mean that you have to write weekly. Â For example, I’m writing this a week before it is scheduled to publish. Â Also, I’m not God – you can post daily, monthly, or irregularly. Â It APPEARS (key word!) that regular posts are better than irregular, but for niche blogs (like transportation modeling and amateur radio), it doesn’t matter as much.
“Marketing” your blog is important. Â If you’re like me (read: not a pro), marketing is about professional clout as opposed to money. Â It occasionally gets help (if you want to see an example, there is a LinkedIn thread where Roger Witte sent me to some pretty useful information). Â Generally, social sharing is the best marketing you can do without spending lots of time marketing. Â No, it isn’t perfect (look how many DOTs block Twitter and Linked In). Â I don’t advocate posting to listserves, either (unless it is relevant to answer a question or the post is a how-to to help people do something that is difficult).
Make sure you use tags in your posts. Â It helps to be able to send someone to www.siliconcreek.net/tags/cube-voyager-c++ as opposed to a list of links. Â It also helps find posts (in the post listing, you can click on the individual tags and see all posts with that tag).
Be wary of where you link to your blog, particularly in other blog’s comments. I occasionally comment on other blogs, but my rule of thumb is that if you’re going to be a troll, you probably don’t want to link to your blog. Â OTOH, if you post a comment that enhances value (is constructive, positive, a question, etc), then linking to your blog is a good thing. Â If you do blogging of a controversial nature, I would be a lot more cautious, as the rules can be very blurry.
Final Words
There will be a lot of things you’ll start to see. Â One is occasional marketing for SEO firms (you’ll see this both as spam email and blog comments). Â In certain worlds, it may make sense to use these services. Â Truthfully, in my world it does not. Â The most SEO you can do is setting up good categories, using social media, providing an RSS feed, and occasionally (and appropriately) pushing your blog via other (generally social) means.
Proofread your posts. Â Don’t ask how many times I didn’t do that only to find a typo a few days later. Â This post was written over a week early and I came back to it a few days later to proofread and clarify things.
Preview your posts, check them when they go live.
Don’t obsess over numbers. Â Obsess over content (if your content is numbers, it is okay to ignore that part about obsessing over numbers). Â And mostly, go with your gut instincts. Â The reason? Story time!
I recently got an email from WordPress that has my “year in review”. Â It wasn’t the best, according to them. Â three of the top 5 posts were from years past. Â However, a few people had mentioned my blog in passing before that, and I had received some interaction from people based on my blog. Â Later, at TRB, a handful of people that I respect A LOT mentioned my blog. Â I’ve had more comments via LinkedIn than… ever (that might have something to do with starting to post to LinkedIn this year 🙂 ). Â My gut instinct was that the blog was better this year, and those friends at TRB confirmed that.
Always update WordPress when it wants to.  I’m going to use Michel Bierlaire’s quote: “In all non-trivial software, there is at least one bug”.  Software development is hard work, and it is really hard when the software can be used (and abused) by anyone.  When WordPress finds security issues (and bugs, too), they fix them and issue updates.  YOU WANT THESE UPDATES.
Finally, keep your best year ahead of you.



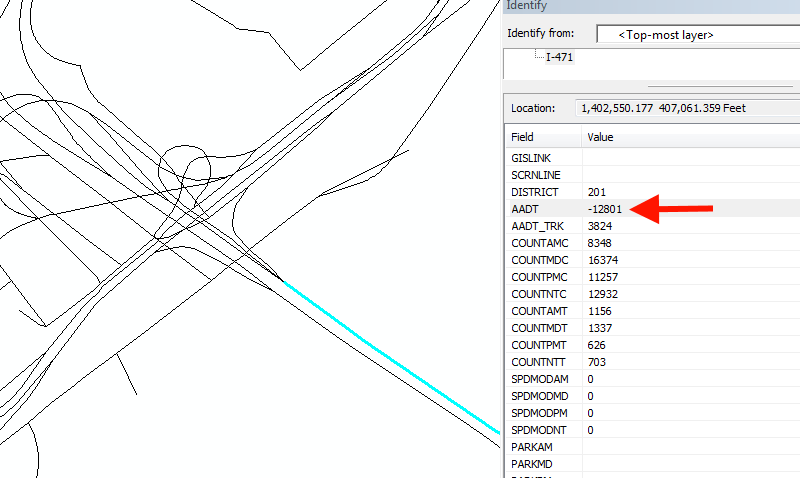
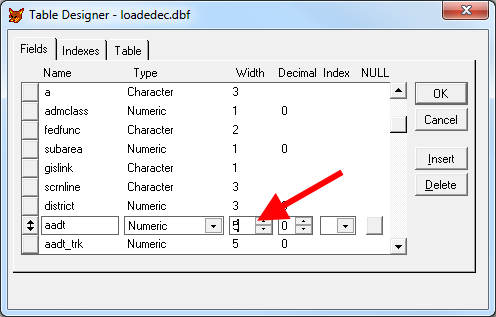
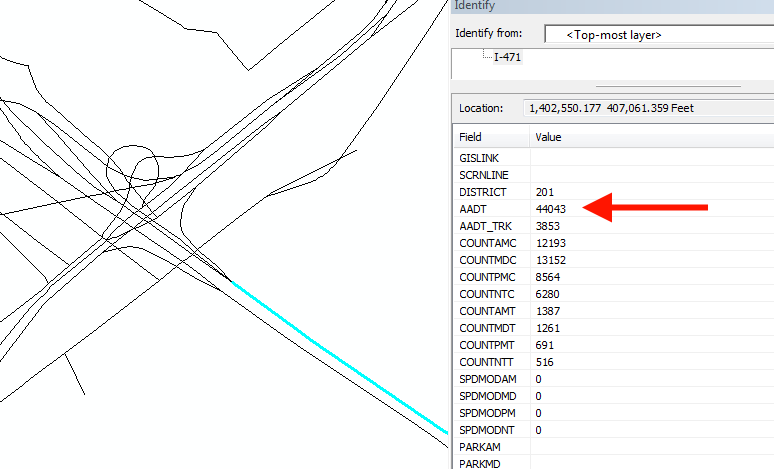
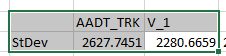






















")

")







